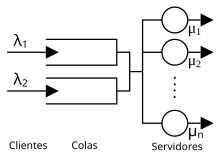
Diagrama que muestra dos colas y múltiples nodos servidores. La teoría de colas estudia los tiempos de espera y capacidad del sistema.
La teoría de colas es el estudio matemático de las colas o líneas de espera dentro de un sistema. Ésta teoría estudia factores como el tiempo de espera medio en las colas o la capacidad de trabajo del sistema sin que llegue a colapsarse. Dentro de las matemáticas, la teoría de colas se engloba en la investigación de operaciones y es un complemento muy importante a la teoría de sistemas y la teoría de control. Se trata así de una teoría que encuentra aplicación en una amplia variedad de situaciones como negocios, comercio, industria, ingenierías, transporte y logística o telecomunicaciones.
La teoría de colas es el estudio matemático de las colas o líneas de espera dentro de un sistema. Ésta teoría estudia factores como el tiempo de espera medio en las colas o la capacidad de trabajo del sistema sin que llegue a colapsarse. Dentro de las matemáticas, la teoría de colas se engloba en la investigación de operaciones y es un complemento muy importante a la teoría de sistemas y la teoría de control. Se trata así de una teoría que encuentra aplicación en una amplia variedad de situaciones como negocios, comercio, industria, ingenierías, transporte y logística o telecomunicaciones.
Los modelos de línea de espera consisten en fórmulas y relaciones matemáticas que pueden usarse para determinar las características operativas (medidas de desempeño) para una cola.
Las características operativas de interés incluyen las siguientes:
Probabilidad de que no haya unidades o clientes en el sistema
Cantidad promedio de unidades en la línea de espera
Cantidad promedio de unidades en el sistema (la cantidad de unidades en la línea de espera más la cantidad de unidades que se están atendiendo)
Tiempo promedio que pasa una unidad en la línea de espera
Tiempo promedio que pasa una unidad en el sistema (el tiempo de espera más el tiempo de servicio)
Probabilidad que tiene una unidad que llega de esperar por el servicio.
Los gerentes que tienen dicha información son más capaces de tomar decisiones que equilibren los niveles de servicio deseables con el costo de proporcionar dicho servicio.
Las características operativas de interés incluyen las siguientes:
Probabilidad de que no haya unidades o clientes en el sistema
Cantidad promedio de unidades en la línea de espera
Cantidad promedio de unidades en el sistema (la cantidad de unidades en la línea de espera más la cantidad de unidades que se están atendiendo)
Tiempo promedio que pasa una unidad en la línea de espera
Tiempo promedio que pasa una unidad en el sistema (el tiempo de espera más el tiempo de servicio)
Probabilidad que tiene una unidad que llega de esperar por el servicio.
Los gerentes que tienen dicha información son más capaces de tomar decisiones que equilibren los niveles de servicio deseables con el costo de proporcionar dicho servicio.
| DISTRIBUCIÓN DE LLEGADAS |
| Para determinar la distribución de probabilidad para la cantidad de llegadas en un período dado, se puede utilizar la distribución de Poisson. /= Media o cantidad promedio de ocurrencia en un intervalo e= 2.17828 X= cantidad de ocurrencias en el intervalo |
 |
| DISTRIBUCIÓN DE TIEMPO DE SERVICIO |
| El tiempo de servicio es el tiempo que pasa un cliente en la instalación una vez el servicio ha iniciado. Se puede utilizar la distribución de probabilidad exponencial para encontrar la probabilidad de que el tiempo de servicio sea menor o igual que un tiempo t. e= 2.17828 μ= cantidad media de unidades que pueden servirse por período |
| DISCIPLINA DE LA LINEA DE ESPERA |
| Manera en la que las unidades que esperan el servicio se ordenan para recibirlo. El primero que llega, primero al que se le sirve Último en entrar, primero en salir Atención primero a la prioridad más alta |
| OPERACIÓN DE ESTADO ESTABLE |
| Generalmente la actividad se incrementa gradualmente hasta un estado normal o estable. El período de comienzo o principio se conoce como período transitorio, mismo que termina cuando el sistema alcanza la operación de estado estable o normal. |
| MODELOS DE LÍNEA DE ESPERA DE UN SOLO CANAL CON LLEGADAS DE POISSON Y TIEMPOS DE SERVICIO EXPONENCIALES |
| A continuación, las fórmulas que pueden usarse para determinar las características operativas de estado estable para una línea de espera de un solo canal. El objetivo de las fórmulas es mostrar cómo se puede dar información acerca de las características operativas de la línea de espera. |
 |
| ¿COMO SE PUEDE MEJORAR LA OPERACION DE LINEA DE ESPERA? |
| Características operativas para el sistema con la tasa media de servicio aumentada a μ=1.25 clientes por minuto. |
 |
 |
 |


 (un
(un  (un solo valor binario) a través de dicha matriz.
(un solo valor binario) a través de dicha matriz.
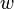 es un vector de pesos reales y
es un vector de pesos reales y 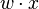 es el
es el 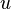 es el 'umbral', el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.
es el 'umbral', el cual representa el grado de inhibición de la neurona, es un término constante que no depende del valor que tome la entrada.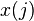 denota el elemento en la posición
denota el elemento en la posición  en el vector de la entrada
en el vector de la entrada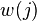 el elemento en la posición
el elemento en la posición  denota la salida de la neurona
denota la salida de la neurona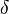 denota la salida esperada
denota la salida esperada es una constante tal que
es una constante tal que 
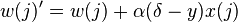
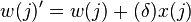
 denota el vector de entrada para la iteración i
denota el vector de entrada para la iteración i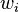 denota el vector de peso para la iteración i
denota el vector de peso para la iteración i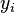 denota la salida para la iteración i
denota la salida para la iteración i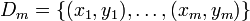 denota un periodo de aprendizaje de
denota un periodo de aprendizaje de  iteraciones
iteraciones en
en 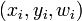 a la regla de actualización
a la regla de actualización 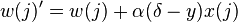
 se dice que es separable linealmente si existe un valor positivo
se dice que es separable linealmente si existe un valor positivo  y un vector de peso
y un vector de peso 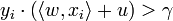 para todos los
para todos los  .
. .
.